Technische und modellierungsnahe Umsetzungsdokumentation des Wissensnetzes
Das Wissensnetz ist nicht nur eine Visualisierung, sondern ein modellierter, typisierter Wissensgraph der Schulinformatik.
Auf der Vorderbühne sieht man Knoten, Kanten, Farben und Fokus. Hinter den Kulissen wirken Fachmodell, Persistenz, API-Mapping, Kontext-Policies und Renderlogik zusammen.
Wissensnetz: Modell, Verarbeitung und Darstellung
1. Warum diese Kulissen-Seite? Anschluss an die D-Book-Konzeption
Die Seite Konzeption des D-Book begründet das Warum: epistemische Zugriffsebenen, didaktische Reduktion, relationale Wissensorganisation.
Diese Kulissen-Seite dokumentiert das Wie: welche Modellobjekte, Persistenzstrukturen, API-Payloads, Filter- und Traversierungsschritte sowie Darstellungsebenen die Umsetzung tragen.
D-Book als lernbares Informatiksystem
Das D-Book ist nicht nur Medium. Es kann selbst Gegenstand informatischer Analyse sein: als Zusammenspiel von Datenmodell, API, Laufzeitverarbeitung und View-Regeln.
Leitdifferenz: Konzeption = Begründungsebene, Kulissen = Umsetzungs- und Modellierungsebene.
Vom Konzept zur Umsetzung: der rote Faden
Die Konzeption beschreibt das D-Book als Lern- und Wissensarchitektur. Diese Kulissen-Seite zeigt die technische Operationalisierung: wie derselbe fachliche Kern in Datenmodell, API, Runtime und Darstellung wirksam wird.
Der Übergang folgt einer didaktischen Bewegungslogik: Inhaltsseite -> Concept -> Relation -> Context/View -> sichtbarer Teilgraph -> Lernhandlung. Damit wird keine beliebige Technikreihenfolge dokumentiert, sondern ein fachlich begründeter Umsetzungsweg.
Concepts stabilisieren Bedeutung, Relations machen Zusammenhänge explizit, Context und ContextDefinition ordnen curricular ein, und die View Policy reduziert sichtbar, ohne den Modellkern zu verändern. Views sind Zugriffsebenen, nicht neue Wahrheiten.
Konzeptionsbegriffe in der Umsetzung
Semantischer Kern
Concept ist die Primäreinheit des Wissenskerns. Relation und RelationType modellieren typisierte, gerichtete Bedeutungsbezüge statt bloßer Clusternähe. Resource verankert Begriffe in Seiten, Glossar, Werkzeugen und Materialien.
Kontextualisierung
Context beschreibt den curricularen Verwendungszusammenhang. ContextDefinition erlaubt kontextspezifische Erklärung desselben Concepts. View und View Policy steuern Fokus, Distanz, Reduktion und Sichtbarkeit, ohne den semantischen Kern zu duplizieren.
Epistemische Zugriffsebenen
Inhaltsseite, Glossar/Inline-Erklärung, Wissensnetz sowie Werkzeug- und Aufgabenebene erfüllen unterschiedliche Erkenntnisfunktionen: erklären, definieren, relational einordnen, anwenden und reflektieren.
Aufgabe und Lernmodus schließen an denselben Concept-Kern an. Übergänge zwischen den Ebenen sind daher nicht nur Navigationstechnik, sondern didaktische Struktur.
D-Book als System
Das D-Book ist Quelle des Lernens (Inhalte, Begriffe, Relationen, Werkzeuge) und zugleich Gegenstand des Lernens (Modellierungs- und Architekturentscheidungen im realen System).
Prozessmodell: Progressive Begriffserschließung im D-Book
Die Bewegung ist nicht beliebige Navigation, sondern epistemische Arbeit am Begriffszusammenhang: Jede Station leistet eine andere Form des Verstehens auf demselben Concept-Kern.
Schritt
Leistung der Ebene
beteiligte technische Struktur
epistemische Funktion
Inhaltsseite
lokale Erklärung, Kontext, Problemstellung
HTML-Content, Seitenstruktur
erklärend
Inline-Erklärung
Begriff sofort im Lesefluss klären
Inline-Overlay, Resolve-Schicht
definierend
Glossar
stabile Definition und Referenz
Glossar, Begriffsanker
definierend / sichernd
Embedded Kapitelnetz
lokale Relationen im Kapitelkontext sehen
knowledge-net-embed-module, pageFilter
relational orientierend
Wissensnetz-View
größere Begriffszusammenhänge analysieren
wissensnetz.js, Fokus/Distanz/View-Policy
relational analytisch
Werkzeug/Aufgabe
Begriffe operativ anwenden und prüfen
ToolResources, Werkzeugseiten, Aufgaben
handelnd
Lernmodus/Rekonstruktion
Wissen erinnern, formulieren, rückbinden
Lernmodus, Rückmeldelogik
reflektierend
2. Technische Komponenten als Lerngegenstände im D-Book
Das Wissensnetz ist nicht nur ein Feature, sondern ein realisiertes Informatiksystem. Damit wird der technische Unterbau selbst zum Lerngegenstand: Die Plattform zeigt nicht nur Inhalte, sondern macht Web-, Datenbank-, Graph- und Architekturprinzipien am laufenden System sichtbar.
Diese technische Perspektive ist nicht von der Fachkonzeption getrennt. Jede Komponente des Wissensnetzes kann als realer Anknüpfungspunkt an Unterrichtsinhalte gelesen werden: E1 erklärt Erreichbarkeit und Client-Server-Kommunikation, E2 die Dokumentstruktur, E3 die Programmierlogik, E4 den Projektcharakter, Q2.1 das Datenmodell, Q2.2 die Abfragen, Q2.3 die Webdatenbankarchitektur und Q2.4 die Grenzen durch Datenschutz und Datensicherheit.
Die Inhaltsseite liefert den didaktischen Kontext. HTML strukturiert und verankert die Einbettung, CSS gestaltet Lesbarkeit und responsive Nutzung, JavaScript lädt und verarbeitet den Graphen, PHP stellt API-Endpunkte bereit, und die Datenbank persistiert Concepts, Relations, Resources und Contexts. SQL mit Joins und Views bereitet daraus Such-, Workbench- und Runtime-Sichten auf. Hosting, Client-Server-Kommunikation sowie Datenschutz und Datensicherheit setzen den operativen und rechtlichen Rahmen.
Diese Zuordnung ist nicht als nachträgliche Themenliste gemeint. Sie zeigt, dass das Wissensnetz selbst ein integratives Beispiel für die D-Book-Inhalte ist.
Komponenten, Rollen und D-Book-Anknüpfung
technische Komponente
Rolle im Wissensnetz
D-Book-Anknüpfung
Lernfrage
Host / Provider / Deployment
stellt Website, Assets und API erreichbar bereit
E1 Internetprotokolle, Q2.3 Webdatenbankprojekt
Wie wird aus lokalen Dateien ein erreichbares Websystem?
HTML
strukturiert Inhaltsseiten und bindet Wissensnetz-Embeds ein
E2 HTML-Dokumente, Q2.3 Webdatenbankprojekt
Wie wird ein semantischer Lerninhalt in eine Webstruktur eingebettet?
CSS
gestaltet Oberfläche, Lesbarkeit, D-Book-Look und responsive Darstellung
E2 HTML-Dokumente, E4 Programmierprojekt
Wie beeinflusst Gestaltung die Nutzbarkeit eines Lernsystems?
JavaScript
lädt Daten, erzeugt Runtime-Modell, filtert, traversiert, rendert und reagiert auf Interaktion
E3 Grundlagen der Programmierung, Q1.5 Graphen, Q2.3 Webdatenbankprojekt
Wie wird aus Daten eine interaktive Darstellung?
PHP
vermittelt zwischen Frontend und Datenbank, liefert API-Payloads
Q2.3 Webdatenbankprojekt
Wie erzeugt ein Server dynamische Daten für eine Website?
Datenbank
speichert Concepts, Relations, Resources, Contexts und Verknüpfungen
Q2.1 ER- und Relationenmodell
Wie modelliert man Wissen relational?
SQL / Joins / Views
fragt Daten ab, verbindet Tabellen, bereitet Such-, Workbench- und Runtime-Daten vor
Q2.2 SQL, Q2.5 Relationenalgebra
Wie entstehen aus Tabellen fachliche Aussagen und Teilgraphen?
API / JSON-Payload
übersetzt Datenbankstrukturen in konsumierbare Frontend-Daten
Q2.3 Webdatenbankprojekt
Wie kommunizieren Frontend und Backend?
Graphlogik / Traversierung
berechnet Nachbarschaft, Fokus, Ordnung 1/2/3 und sichtbare Teilgraphen
Q1.5 Graphen, Q2.2 SQL, Q2.5 Relationenalgebra
Wie wird aus relationalen Daten ein Graphausschnitt?
Datenschutz und Datensicherheit
begrenzt, welche Daten gespeichert, ausgeliefert und sichtbar gemacht werden
Q2.4 Datenschutz und Datensicherheit
Welche Daten darf ein Lernsystem speichern, anzeigen und verarbeiten?
Projektorganisation / Weiterentwicklung
Wissensnetz ist ein wachsendes System mit Versionen, Kuration, Tests und Iterationen
E4 Programmierprojekt, Q2.3 Webdatenbankprojekt
Wie wird ein komplexes Informatiksystem geplant, gepflegt und erweitert?
3. Wie das Wissensnetz aufgebaut wird
Sequenzdiagramm des Aufbauprozesses
Drei-Ebenen-Pipeline des Wissensnetzes
DB / Concept-System reich
Concepts
Relations
Resources
Contexts
→
API / Views / Kontextfilter reduziert
freigegebene Such-/Workbench-Schicht (z. B. v_search_*)
Runtime-Endpoint mit Queries, Joins, Mapping, Snapshot-Fallback
v_search_concepts, v_search_concept_relations und v_search_concept_resources stehen hier als freigegebene View-/Such-/Workbench-Schicht bzw. Architekturprinzip.
Der aktuelle Runtime-Endpoint kann die Daten zusätzlich über konkrete SQL-Queries, Joins und Mapping-Strukturen bereitstellen. Entscheidend ist die Trennung der Ebenen, nicht eine einzige technische Abfrageform.
Das Wissensnetz ist als relationales, semantisches Modell angelegt, weil Begriffe nicht isoliert stehen. Fachliche Bedeutung entsteht aus typisierten Beziehungen, Kontexten und verankerten Ressourcen.
Concept ist die zentrale Bedeutungseinheit. Es ist keine reine Wortmarke, sondern ein kuratierter Begriffsknoten mit stabiler Identität.
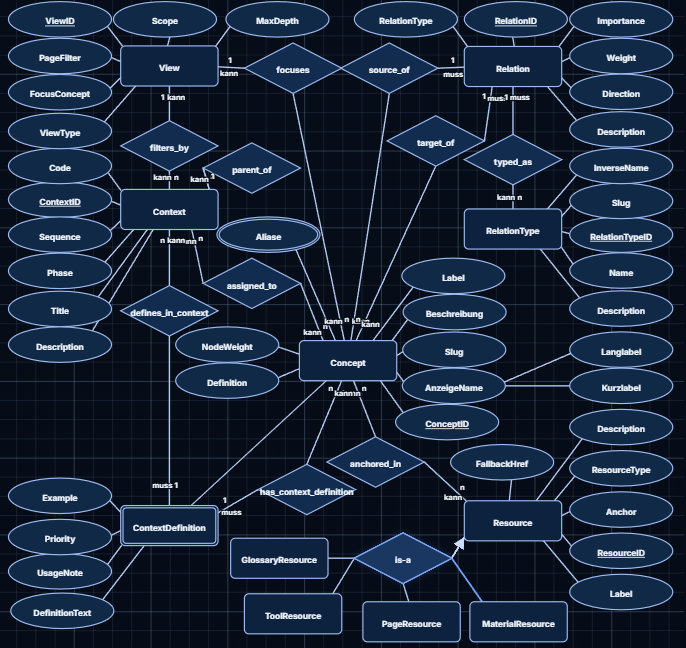
Relationales Kernmodell des Wissensnetzes
Vor der Grafik: Erkennbar werden soll die Trennung von Bedeutungsobjekt (Concept), Beziehung (Relation), Bedeutungstyp (RelationType), Verankerung (Resource), Kontext (Context/ContextDefinition) und Darstellungsperspektive (View).
ER-Modell des Wissensnetzes: Concepts bilden die fachlichen Bedeutungsknoten, Relations verbinden Concepts rollenbasiert, Resources verankern Concepts im D-Book und Views reduzieren die Darstellung kontextabhängig.
Nach der Grafik: Das ER-Modell zeigt den persistenten Wissenskern. Es zeigt nicht automatisch die konkrete Sichtbarkeit einer aktuellen Netzansicht.
Selbstreferenz: Concept → Relation → Concept
Concept (source)
conceptId = A
→
ConceptRelation
relationType = typisierte Bedeutung
sourceConceptId = A
targetConceptId = B
→
Concept (target)
conceptId = B
Selbstreferenziell heißt: Eine Relation verweist mit zwei Rollen auf dieselbe Concept-Tabelle (sourceConcept, targetConcept).
Join-Pfade zu fachlichen Aussagen
Pfad A: Beziehungen
Concept → Relation → Concept
Welche Concepts stehen in welcher typisierten Beziehung?
Pfad B: Verankerungen
Concept → ResourceLink → Resource
Wo ist das Concept in Seiten, Glossar, Werkzeugen oder Material verankert?
Resource ist keine bloße URL: Sie ist eine modellierte Verankerung im D-Book-System.
View ist eine reduzierte Perspektive auf denselben Modellkern. View != Wahrheit.
5. Datenbankmodell und persistenter Wissenskern
Persistiert werden nicht nur Begriffsnamen, sondern strukturierte Wissenselemente: Concepts, Relations, RelationTypes, Resources, Concept-Resource-Links, Cluster- und Kontextzuordnungen, ContextDefinitions, Domains, Types, Aliases.
Die Trennung dieser Einheiten dient der Normalisierung: stabile Identitäten, Mehrfachverwendung, Kontextfähigkeit und spätere View-Bildung ohne Vermischung von Darstellung und Fachwahrheit.
Warum die Trennung wichtig ist
stabile Concept-Identität über mehrere Seiten- und Nutzungskontexte
kontextspezifische Erklärung ohne Duplikation des Concept-Kerns
rekonstruierbarer Graph aus relationalen Tabellen über Fremdschlüssel
Layoutdaten sind Darstellungshilfen. Sie ersetzen keine kuratierte Relation.
6. Vom Datenmodell zur API-View und Runtime-Struktur
Frontend und Workbench sollten nicht direkt mit Basistabellen arbeiten. Dazwischen liegt eine freigegebene Aufbereitungsschicht: Such-/Workbench-Views (z. B. v_search_*) sowie Runtime-Endpoints, die Queries, Joins, Mapping und Fallback-Pfade bündeln.
Damit entstehen klar getrennte Schichten: persistente Struktur, API-Ausgabe, Frontend-Runtime-Modell und sichtbare Darstellung.
didaktisch reduzierte Darstellung für konkrete Situation
Reduktion in API oder View ist kein Verlust der Fachwahrheit, sondern kontrollierte Perspektivierung.
7. Verarbeitungspipeline mit gezielten Codeauszügen
7.1 API-Payload-Mapping: persistente Struktur → API-Daten
Der Ausschnitt zeigt, wie aus gelesenen Tabellenstrukturen ein konsolidiertes Payload-Objekt aufgebaut wird. Sichtbar ist die Trennung von Concept-, Relation-, Resource- und Kontextdaten.
Der Ausschnitt zeigt die Normalisierung in ein konsumierbares Runtime-Graphmodell. Er zeigt nicht alle zusätzlichen Metadaten und Deduplizierungsregeln.
Der Ausschnitt zeigt die Sichtbarkeitsschicht zwischen Graphmodell und Darstellung. Er zeigt nicht die vollständige Renderausgabe in 3D/Labeling.
7.8 Embedded Views: Einbettung per data-knowledge-net-*
Kapitelnetze werden per Konfiguration eingebettet. Dadurch entstehen keine separaten Wissensnetze, sondern kontextspezifische Views desselben Modellkerns.
Der Ausschnitt zeigt die Einbettungskonfiguration. Er zeigt nicht die gesamte Initialisierung der Runtime nach dem Mounting.
8. Graphstruktur, Traversierung und Sichtbarkeit
Graphische Grundbegriffe in der Runtime
Concepts = Knoten
Relations = gerichtete, typisierte Kanten
RelationType = semantische Bedeutung der Kante
Nachbarschaft = direkt erreichbare Knoten
Ordnung 1/2/3 = Navigationsdistanz vom Fokusknoten
Ordnung ist Distanzmetrik im Graphen, keine Fachkategorie.
Graphentheoretische Präzisierung für die Umsetzung
Ego-Netz: Die Fokusansicht entspricht einem Ego-Netz um den Fokusbegriff und seine erreichbaren Nachbarn bis zur gesetzten Distanz.
Ordnung 1/2/3: Das sind Graphdistanzen (Anzahl Traversierungsschritte), keine didaktischen Wertigkeiten.
Induzierter Teilgraph: Nach Knotenwahl entstehen sichtbare Kanten nur zwischen den behaltenen Knoten.
Knotenfilter vs. Kantenfilter: Knotenfilter bestimmt, wer im Teilnetz bleibt; Kantenfilter bestimmt, welche Relationen davon sichtbar sind.
Gerichtete Relation vs. Traversierungsnachbarschaft: Eine Relation kann fachlich gerichtet sein, während Traversierung je nach Policy bidirektional erweitert.
Layoutnähe ist keine fachliche Relation: Räumliche Nähe in 2D/3D zeigt Lesbarkeit, nicht automatisch Semantik.
Cluster ist Ordnungshilfe: Cluster strukturieren die Darstellung, ersetzen aber keine begründete Concept-Relation.
Kontext-View: Gesamtnetz vs. Fokus-Ausschnitt
Gesamtnetz (Modellkern)
fachlich vorhanden
Fokus-View
FokusOrdnung 1Ordnung 2Ordnung 3
derzeit sichtbar
Unsichtbar heißt nicht: fachlich nicht vorhanden.
Traversierung berechnet einen sichtbaren Teilgraphen für die aktuelle Frage- und Nutzungssituation. Sie erzeugt keine neue Fachstruktur.
Wichtig ist die Unterscheidung: fachliche Relation (Modell) / graphische Kante (Runtime-Objekt) / sichtbare Kante (Policy-Ergebnis) / räumliche Nähe (Layout).
9. Kontext- und View-Policy-Ebene: Kontext schlägt globale Relevanz
Warum Kapitelnetze anders aussehen als das Gesamtnetz
Kapitelnetze reduzieren den sichtbaren Ausschnitt auf die didaktisch relevante Teilstruktur einer Seite oder Einheit. Embedded Views reduzieren stärker als die große Gesamtansicht, damit Lesbarkeit und Lernfokus erhalten bleiben.
Die Konzeption-Seite beschreibt Views als epistemische Zugriffsebenen. Technisch umgesetzt wird das hier über Filter- und Policy-Logik.
Rollen von PageFilter, FocusConcept und MaxDepth
PageFilter: begrenzt den thematischen/kapitelbezogenen Scope
FocusConcept: setzt den lokalen Analysemittelpunkt
MaxDepth: begrenzt die Traversierungsdistanz
Diese Parameter haben unterschiedliche Aufgaben und wirken kombiniert. Dadurch wird nicht die Fachwahrheit geändert, sondern die Darstellungssicht.
View-Typen und didaktische Funktion
View-Typ
technischer Trigger / Parameter
didaktische Funktion
typische Reduktion
Gefahr der Fehlinterpretation
Gesamtview
Wissensnetz ohne engen Seitenfilter, Overview-Policy
relationalen Überblick aufbauen
starke Komplexitätsreduktion über Policy und Sichtbarkeit
"Nicht sichtbare Relation existiert nicht"
Kapitel-/Overview-View
PageFilter, Structural-Group- oder Kontextscope
curriculare Orientierung im Abschnitt
nur kapitelnahe Concepts/Relationen
"Kapitelgrenze ist Concept-Grenze"
Embedded View
data-knowledge-net-page-filter, variant=embedded, lokale maxDepth
lokale Orientierung im Lesefluss
kleiner Teilgraph mit Fokus auf unmittelbare Nachbarschaft
"Embed zeigt den gesamten Modellkern"
Fokusview
FocusConcept + Distanzberechnung + Focus-Policy
Analyse eines Begriffs im Beziehungsumfeld
Distanz- und Relevanzfilter auf Knoten/Kanten
"Layoutnähe = fachliche Nähe"
Werkzeug-/Aufgabenkontext
Resource-/Tool-Verankerung, Aufgaben- oder Lernmodus-Trigger
Übergang zu Handlung, Anwendung, Reflexion
nur für Handlungssituation nötige Ausschnitte
"Tool ersetzt Begriffs- und Relationsverstehen"
View ist immer didaktische Entscheidung: Sichtbarkeit ist nicht nur technischer Filter, sondern gesteuerte Erschließung.
10. Von der Graphstruktur zur sichtbaren Darstellung
Mapping Fachmodell → sichtbares Netz-Element
Modellseite
View-/UI-Seite
Concept
Knoten
Concept label
Knotenlabel
Concept relation
Kante
RelationType
Kantenlabel / Kantentyp
Resource
Link / Anker / Materialverweis
Context / page filter
Sichtbarkeit / Hervorhebung
nodeWeight / importance
visuelle Priorisierung
Position, Abstand, Clusterlage und Sphere-Geometrie sind Darstellungshilfen, keine fachlichen Relationen.
Nodes entstehen aus Concepts, Links aus Relations. Farben, Größen, Opacity und Hervorhebungen entstehen aus Relationstypen, Fokusdistanz, Gewichtungen und Policy-Regeln.
Cluster dienen als semantische Container bzw. didaktische Ordnungshilfe. Die 3D-/Sphere-Ansicht verbessert räumliche Orientierung, ersetzt aber keine fachliche Modellierung.
11. Kapitelnetze und Embedded Views
Kapitelnetze sind keine separaten Wissensnetze. Sie sind kontextspezifische Views auf denselben Modellkern.
data-knowledge-net-*-Attribute konfigurieren Einbettung, Scope und Darstellungsmodus (z. B. Variant, PageFilter, ClusterMode, LayoutMode).
Didaktischer Anker und relationale Zugriffsebene
Die Inhaltsseite bleibt didaktischer Anker (Erklärung, Progression, Aufgabenkontext). Das eingebettete Wissensnetz ergänzt als relationale Zugriffsebene.
Reduzierter Sichtausschnitt in Embeds bedeutet nicht reduzierten Modellkern.
12. Vom relationalen Wissen zur Lernhandlung
Werkzeuge, Aufgaben und Lernmodus sind operative Anschlussstellen der Wissensarchitektur. Sie sind keine isolierten Zusatzmodule.
Die technische Architektur ist dabei selbst anschlussfähig an konkrete Kapitel: von E1/E2/E3/E4 bis Q2.1-Q2.4.
Resources können daher auch ToolResources sein: Verankerungen eines Concepts in interaktiven Werkzeugen oder Materialsituationen.
Didaktischer Übergang
lesen und verstehen
vergleichen und einordnen
modellieren und simulieren
ausführen und prüfen
reflektieren und sichern
Damit folgt die technische Umsetzung der Konzeption: vom Dokumentraum zur handlungsorientierten Lernarchitektur.
D-Book als lernbares Informatiksystem im Unterricht
Die Kulissen-Seite kann als Analysefläche für mehrere informatische Ebenen genutzt werden: ER-Modellierung (Concept, Relation, Resource), Relationenmodell und Join-Pfade, API-Payloads und Mapping, Graphtraversierung (Adjacency, Distanz, Ego-Netz), View-Logik (Filter, Fokus, Reduktion), Embedded-Komponenten sowie Darstellungs- und Layoutschichten.
Damit wird die D-Book-Konzeption konkret operationalisiert: Das D-Book bleibt Quelle des Lernens (Inhalte, Begriffe, Werkzeuge) und wird zugleich Gegenstand des Lernens (Modellierungs- und Architekturentscheidungen an einem realen System).
13. Grenzen und Entwicklungscharakter der Umsetzung
Kuratiert, evolutiv, überprüfbar
Das Wissensnetz ist ein kuratiertes, evolutives Modell. Es ist keine vollständige Abbildung der Informatik.
Relationstypen, Concept-Grenzen, Context-Zuordnungen und View-Policies bleiben überprüfbar und revidierbar.
Automatisierung und Kuration
Automatisierung kann Kuration unterstützen, aber nicht ersetzen. Runtime-Heuristiken dürfen fachliche Setzungen nicht stillschweigend überschreiben.
Darstellung erzeugt keine neue fachliche Wahrheit.
14. Kurzfazit: Konzeption erklärt das Warum, Kulissen zeigt das Wie
Die Konzeption-Seite begründet die Architektur als epistemische und didaktische Entscheidung. Diese Kulissen-Seite operationalisiert dieselben Begriffe technisch: Modellobjekte, Persistenz, API-Aufbereitung, Runtime-Traversierung, View-Policies und Darstellung.
So bleibt nachvollziehbar, wie ein reiches Concept-System in unterschiedliche, didaktisch sinnvolle Views übersetzt wird, ohne den Modellkern mit der sichtbaren Oberfläche zu verwechseln.