In E3 wurden Arrays als erste strukturierte Datenform verwendet:
Mehrere Werte liegen geordnet vor, werden über Indizes angesprochen und mit Schleifen oder Methoden verarbeitet.
In Q1.1 wurden Objekte, Attribute, Methoden und Referenzen modelliert.
Q1.4 verbindet beides: Höhere Datenstrukturen organisieren mehrere Objekte so, dass bestimmte Operationen
– Durchlaufen, Einfügen, Löschen, Aktualisieren, Suchen oder Abarbeiten – gezielt möglich werden.
Entscheidend ist nicht nur, welche Daten vorhanden sind, sondern welche Operationen auf ihnen sinnvoll,
sicher und effizient möglich sein sollen.
Die Renderer dieser Seite sind Werkzeuge zur Veranschaulichung. Ausgangspunkt ist aber die fachliche Frage:
Welche Datenorganisation, welche Operationen und welche Invarianten passen zum Problem?
Kerncurriculum kompakt Modellierung, Operationen und Niveauunterschiede
Das Kerncurriculum verlangt hier keine Sammlung auswendig gelernter Strukturen. Im Mittelpunkt steht,
Strukturen objektorientiert zu modellieren, ihre Operationen zu erklären und die Strukturwahl fachlich zu begründen.
Grundlegendes Niveau (Grundkurs und Leistungskurs)
Lineare, referenzbasierte Strukturen:
lineare Listen objektorientiert modellieren
Knoten durchlaufen, einfügen, löschen und aktualisieren
Stapel und Warteschlange als Zugriffsbeschränkungen verstehen
Erhöhtes Niveau (Leistungskurs)
Hierarchische Strukturen:
binäre Bäume objektorientiert modellieren
Such-, Einfüge-, Lösch-, Aktualisierungs- und Traversierungsoperationen erklären
Ordnungsregeln als Invarianten nutzen
Arbeitsfokus: Beschreibe zu jeder Struktur zuerst das Modell, dann die erlaubten Operationen und erst danach eine mögliche Implementierung.
Von Arrays und Objekten zu Datenstrukturen E3 und Q1.1 als fachliche Grundlage
E3 hat gezeigt: Ein Array speichert mehrere Werte geordnet und erlaubt direkten Zugriff über einen Index.
Diese Struktur ist stark, solange Größe und Positionen gut planbar sind. Sie wird aber unhandlich, wenn Daten
dynamisch wachsen, häufig in der Mitte eingefügt oder gelöscht werden oder nicht linear, sondern hierarchisch organisiert sind.
Q1.1 liefert die zweite Grundlage: Objekte können Attribute, Methoden und Referenzen besitzen. Aus einem Objekt
wird ein Knoten, wenn es neben seinem Inhalt auch Verweise auf andere Knoten trägt. Aus einzelnen Knoten entsteht
eine Datenstruktur, wenn Referenzen, Operationen und Regeln zusammenpassen.
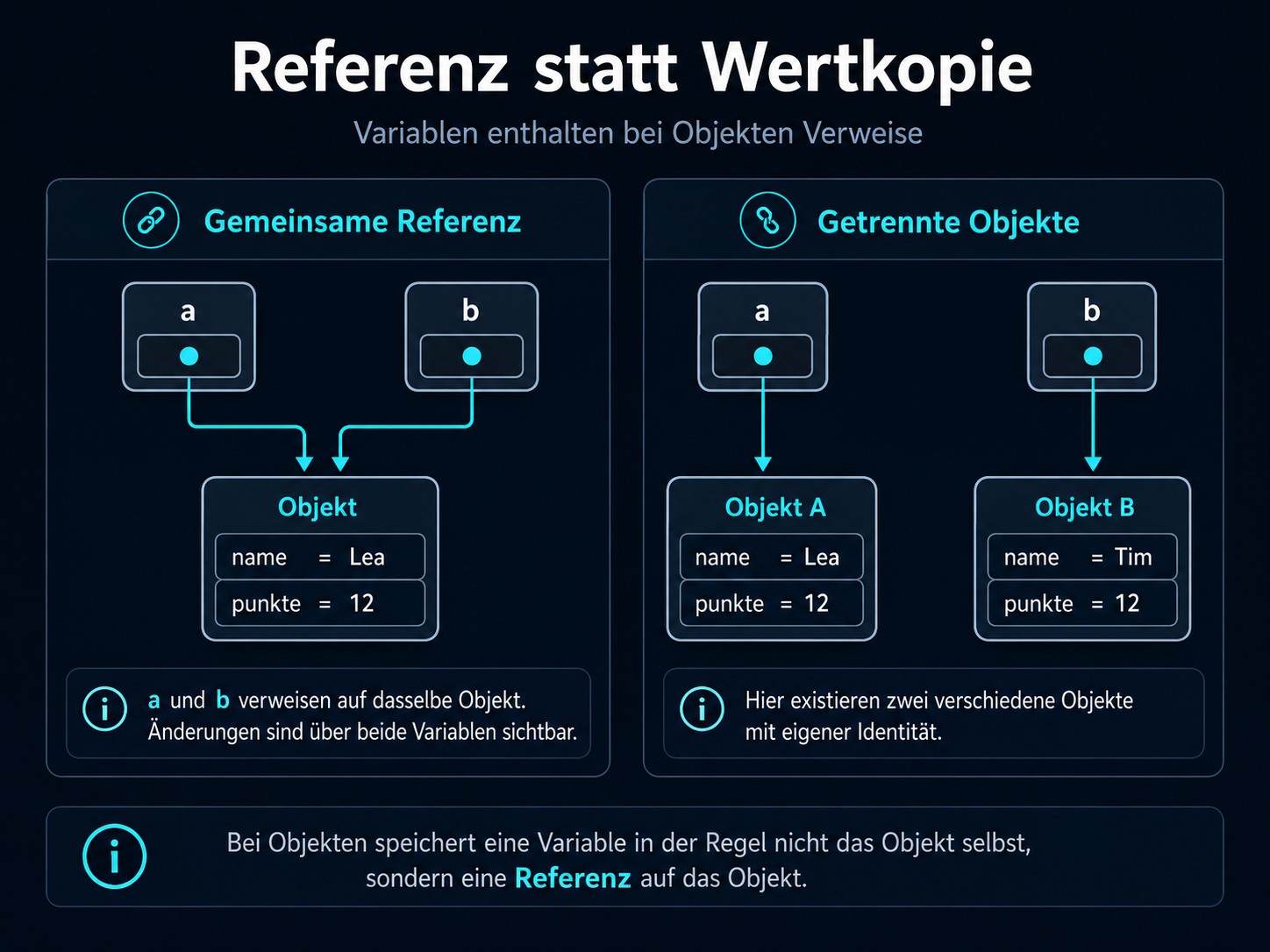
Aus Q1.1 ist bekannt: Objekte werden nicht wie primitive Werte einfach kopiert. Variablen enthalten bei Objekten
in der Regel Referenzen. Genau diese Idee wird in Q1.4 zur Strukturidee: Datenstrukturen entstehen, indem Objekte
über Referenzen miteinander verbunden werden.
Referenzen verbinden Variablen mit Objekten; mehrere Variablen können dasselbe Objekt erreichen.
Für verkettete Listen bedeutet das: Die Liste besteht nicht aus nebeneinanderliegenden Speicherzellen wie ein Array.
Stattdessen verweisen Knotenobjekte auf Nachfolger. Wer Referenzen versteht, kann nachvollziehen, warum Einfügen
und Löschen bei verketteten Listen als Umlenken von Verweisen modelliert wird.
Strukturidee
Array / Datenfeld
Verkettete Liste
Position
durch Index
durch Pfad ab head
Ordnung
durch Speicherposition
durch next-Referenzen
Zugriff
direkt auf a[i]
schrittweise durch Traversieren
Strukturänderung
oft mit Verschieben verbunden
oft durch Umlenken lokaler Referenzen
Eine Datenstruktur besteht damit aus drei zusammengehörigen Ebenen: Organisationsform, Operationen und Invarianten.
Ein abstrakter Datentyp trennt zusätzlich die Frage Was darf man tun? von der Frage Wie ist es implementiert?
Anforderungen an eine Datenstruktur Von der Situation zum Operationsprofil
Stell dir eine Lerngruppe vor, die Quellenkarten für ein Referat sammelt. Neue Bücher und Webseiten kommen dazu,
einzelne Karten werden umsortiert, fehlerhafte Angaben werden aktualisiert, manche Karten werden entfernt und am Ende
sollen die Quellen in einer begründeten Reihenfolge abgearbeitet werden. Eine andere Situation wäre ein Bücherstapel:
Das zuletzt aufgelegte Buch liegt oben. Eine Warteschlange arbeitet dagegen die zuerst Angekommenen zuerst ab.
Aus solchen Alltagssituationen entsteht die fachliche Frage nicht „Welche Struktur kenne ich?“, sondern:
Welche Operationen treten häufig auf, und welche Regeln dürfen dabei nicht verletzt werden?
Datenmenge
Ist die Größe fest planbar oder wächst die Sammlung dynamisch?
Zugriff
Muss häufig eine Position direkt gelesen werden oder reicht schrittweises Traversieren?
Änderung
Wird vorne, hinten oder in der Mitte eingefügt, gelöscht und aktualisiert?
Ordnung
Muss Reihenfolge erhalten bleiben, gilt LIFO/FIFO oder gibt es eine Hierarchie?
Operationsprofil
Ein Operationsprofil beschreibt, welche Operationen besonders wichtig sind: get, set,
insert, remove, traverse, push, pop,
enqueue, dequeue, search oder Traversierungen im Baum.
Folgerung
Erst das Operationsprofil begründet die Datenstrukturwahl. Häufiger Indexzugriff spricht für ein Array;
häufige lokale Referenzänderung für eine verkettete Liste; geregeltes Abarbeiten für Stack oder Queue;
Hierarchie und Suchräume für Bäume.
Arbeitsauftrag: Notiere für „Quellenkarten sammeln“ drei häufige Operationen und entscheide, ob ein Array, eine verkettete Liste, ein Stack oder eine Queue naheliegt.
ADT: Operationen vor Implementierung Der Vertrag einer Datenstruktur
Ein abstrakter Datentyp ist ein Vertrag: Er beschreibt, welche Operationen erlaubt sind und welches Verhalten
sie haben. Die konkrete Speicherung bleibt zunächst offen. Eine lineare Liste erlaubt zum Beispiel Zugriff,
Aktualisierung, Einfügen, Löschen und Durchlaufen einer geordneten Folge.
Was-Ebene
get(i) liefert ein Element, set(i, wert) aktualisiert einen Inhalt,
insert(i, wert) fügt ein Element ein, remove(i) entfernt eines,
traverse() besucht die Elemente in Reihenfolge.
Wie-Ebene
Dieselbe Liste kann intern durch ein Array oder durch Knoten mit Referenzen implementiert werden.
Diese zweite Entscheidung beeinflusst Laufzeit, Speicherbedarf und Änderungsaufwand.
interface Liste<T> {
int length();
boolean isEmpty();
T get(int index);
void set(int index, T value);
void insert(int index, T value);
T remove(int index);
}
Der Bezug zu Q1.1 ist direkt: Ein ADT ist eine fachliche Schnittstelle. Konkrete Klassen implementieren diese
Schnittstelle und kapseln ihre interne Darstellung nach dem Geheimnisprinzip.
Die folgende Rendererfläche zeigt eine lineare Folge als ADT-Idee: sichtbar ist die Reihenfolge, nicht die interne Speicherung.
Die Deutung ist absichtlich abstrakt: Die Operationen sprechen über eine geordnete Folge. Ob die Folge später
in einem Datenfeld oder in Knoten liegt, ist noch nicht entschieden.
Arbeitsauftrag: Ergänze zu drei Operationen aus dem Interface je eine Vorbedingung oder Nachbedingung, zum Beispiel „Index muss gültig sein“.
Array-basierte Liste Direktzugriff, Aktualisieren und Verschiebungskosten
Die array-basierte Liste greift die E3-Erfahrung mit Datenfeldern wieder auf. Ein Array speichert Werte an
nummerierten Positionen. Deshalb ist get(i) stark: Die Position ist über den Index unmittelbar bestimmbar.
Der einfache Fall ist Aktualisieren: set(i, wert) verändert den Inhalt einer vorhandenen Zelle.
Die Struktur bleibt gleich. Einfügen und Löschen sind dagegen Strukturänderungen: Nachfolgende Elemente müssen
häufig verschoben werden, damit die Reihenfolge und die lückenlose Indexstruktur erhalten bleiben.
class ArrayListe {
private int[] daten;
private int anzahl;
int get(int index) {
return daten[index];
}
void set(int index, int wert) {
daten[index] = wert; // Inhalt ändert sich, Struktur bleibt gleich
}
}
Beispiel: Einfügen an Position 1
Vor dem Renderer steht die Vorfrage: Welche Elemente müssen ihren Platz verlassen, damit an Position 1 ein
neuer Wert eingefügt werden kann?
Deutung der Darstellung
Direktzugriff:get(i) ist schnell, weil die Position berechnet werden kann.
Einfügen: Elemente rechts von der Einfügestelle müssen verschoben werden.
Löschen: Elemente rechts vom gelöschten Element rücken nach links.
Aktualisieren: Nur value ändert sich; die Positionen bleiben erhalten.
Methodenbezug
In einer Listenklasse werden get, set, insert und remove
als Methoden modelliert. Die Klasse entscheidet intern, wann verschoben oder Kapazität erweitert werden muss.
Arbeitsauftrag: Begründe, warum set(2, 99) methodisch anders zu bewerten ist als insert(2, 99).
Verkettete Liste und Knotenmodell Objektstruktur, Referenzen und lokale Operationen
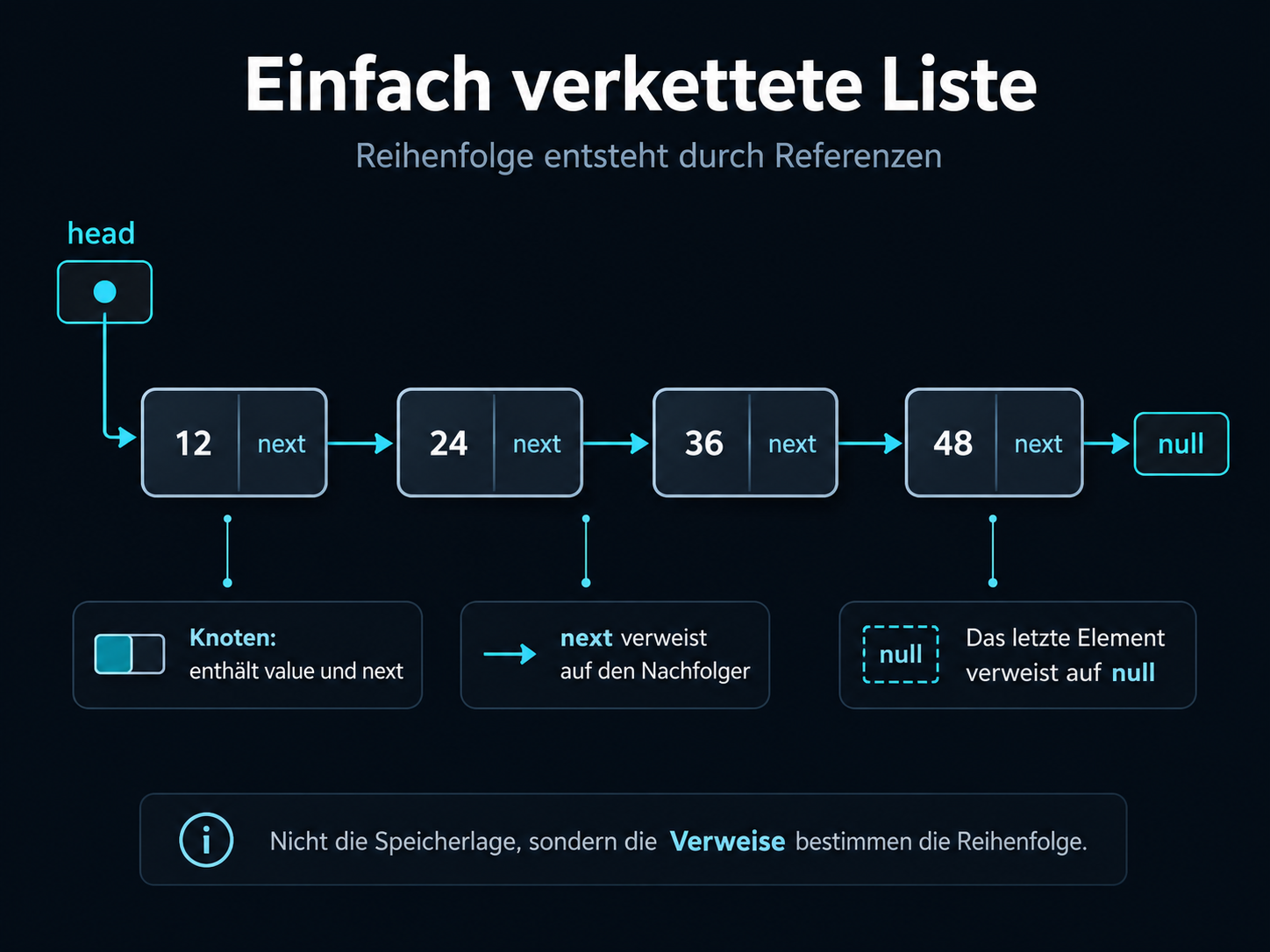
Die verkettete Liste ist der zentrale Q1.1-Anschluss in Q1.4. Ein Knoten ist ein Objekt mit Inhalt
und Referenz: value speichert den Inhalt, next verweist auf den nächsten Knoten.
Die Liste besitzt mit head einen Einstiegspunkt; je nach Implementierung kommen tail
und current als Arbeitsreferenzen hinzu.
Bevor einzelne Operationen betrachtet werden, muss das Grundmodell der verketteten Liste klar sein:
Ein Knoten speichert nicht nur einen Wert, sondern auch eine Referenz auf den nächsten Knoten. Die Liste besitzt
mit head einen Einstiegspunkt. Von dort aus wird die Struktur Schritt für Schritt über
next-Referenzen erschlossen.
In einer verketteten Liste entsteht Reihenfolge über next-Verweise.
Diese Darstellung macht zugleich die Grenze gegenüber dem Array sichtbar. Beim Array ist die Position über den
Index unmittelbar erreichbar. In der verketteten Liste entsteht Position erst durch den Weg: Man beginnt bei
head und folgt den next-Verweisen, bis der gesuchte Knoten erreicht ist.
class Node {
int value;
Node next;
Node(int value) {
this.value = value;
}
}
Strukturmodell und Renderer
Die Abbildung sichert die Grundidee. Der Renderer zeigt anschließend dieselbe Struktur im Seitenkontext
und macht sichtbar, welche Knoten beim Traversieren fokussiert werden.
Traversieren statt Direktzugriff
Traversieren bedeutet: current wandert entlang der next-Referenzen. Jede Bewegung
folgt genau einer Verbindung. Deshalb ist der Zugriff auf eine spätere Position pfadbasiert und nicht direkt.
Node current = head;
while (current != null) {
verarbeite(current.value);
current = current.next;
}
Die fachliche Folgerung: Positionen sind in der verketteten Liste keine festen Adressen, sondern Ergebnisse
einer Such- oder Laufbewegung.
Lokales Einfügen hinter current
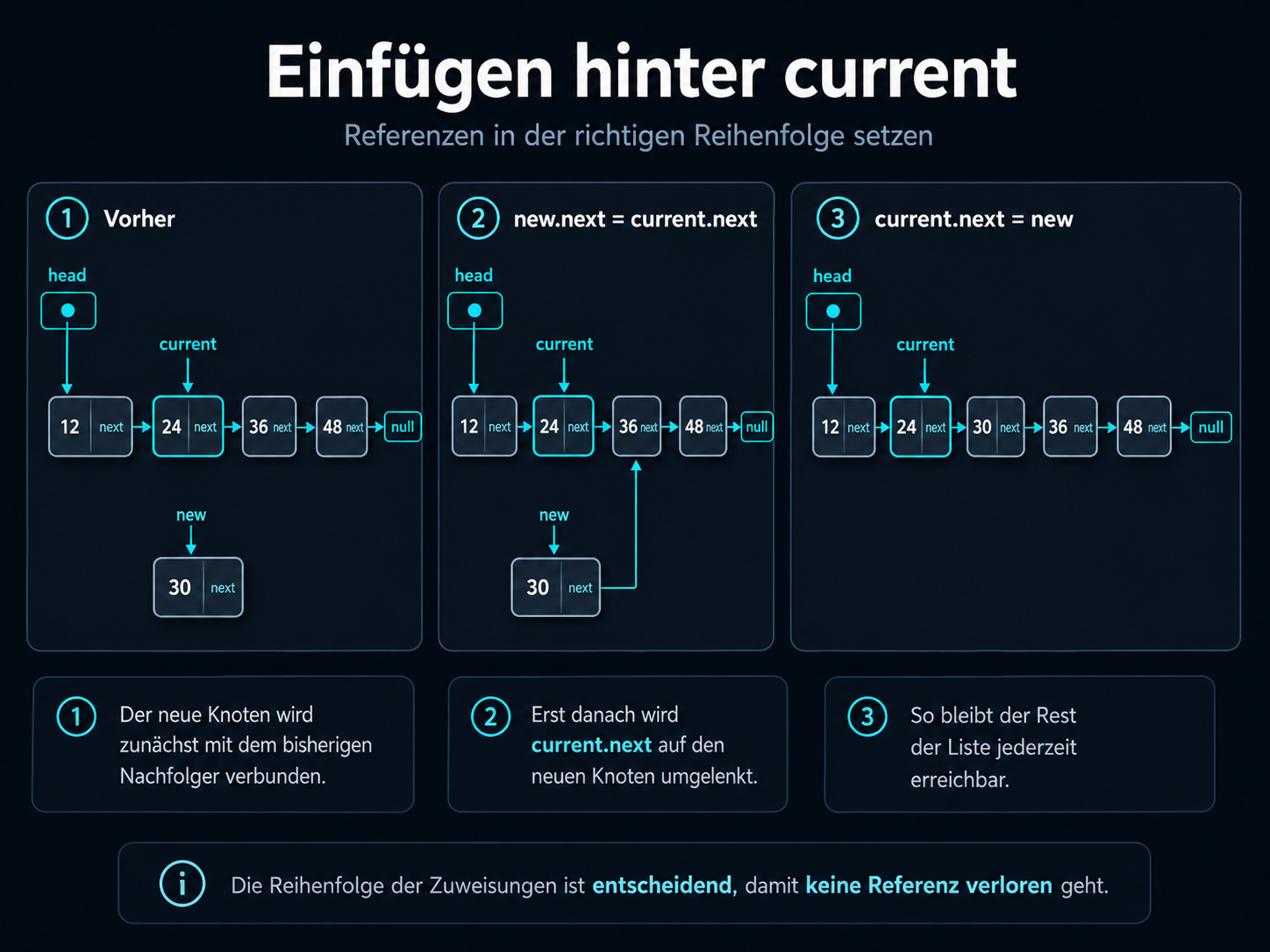
Beim Einfügen ist nicht nur entscheidend, dass ein neuer Knoten entsteht. Entscheidend ist die Reihenfolge
der Referenzänderungen. Wird zuerst current.next auf den neuen Knoten gesetzt, ohne den bisherigen
Nachfolger zu sichern, kann der Rest der Liste unerreichbar werden.
Beim Einfügen muss zuerst der bisherige Nachfolger gesichert werden.
Die Abbildung zeigt deshalb die sichere Reihenfolge: Zuerst übernimmt der neue Knoten mit
new.next den bisherigen Nachfolger. Erst danach wird current.next auf den neuen
Knoten umgelenkt. So bleibt die Restliste während der gesamten Operation erreichbar.
Der Renderer zeigt die Operation zusätzlich als schrittweise Strukturveränderung innerhalb der Seitenlogik.
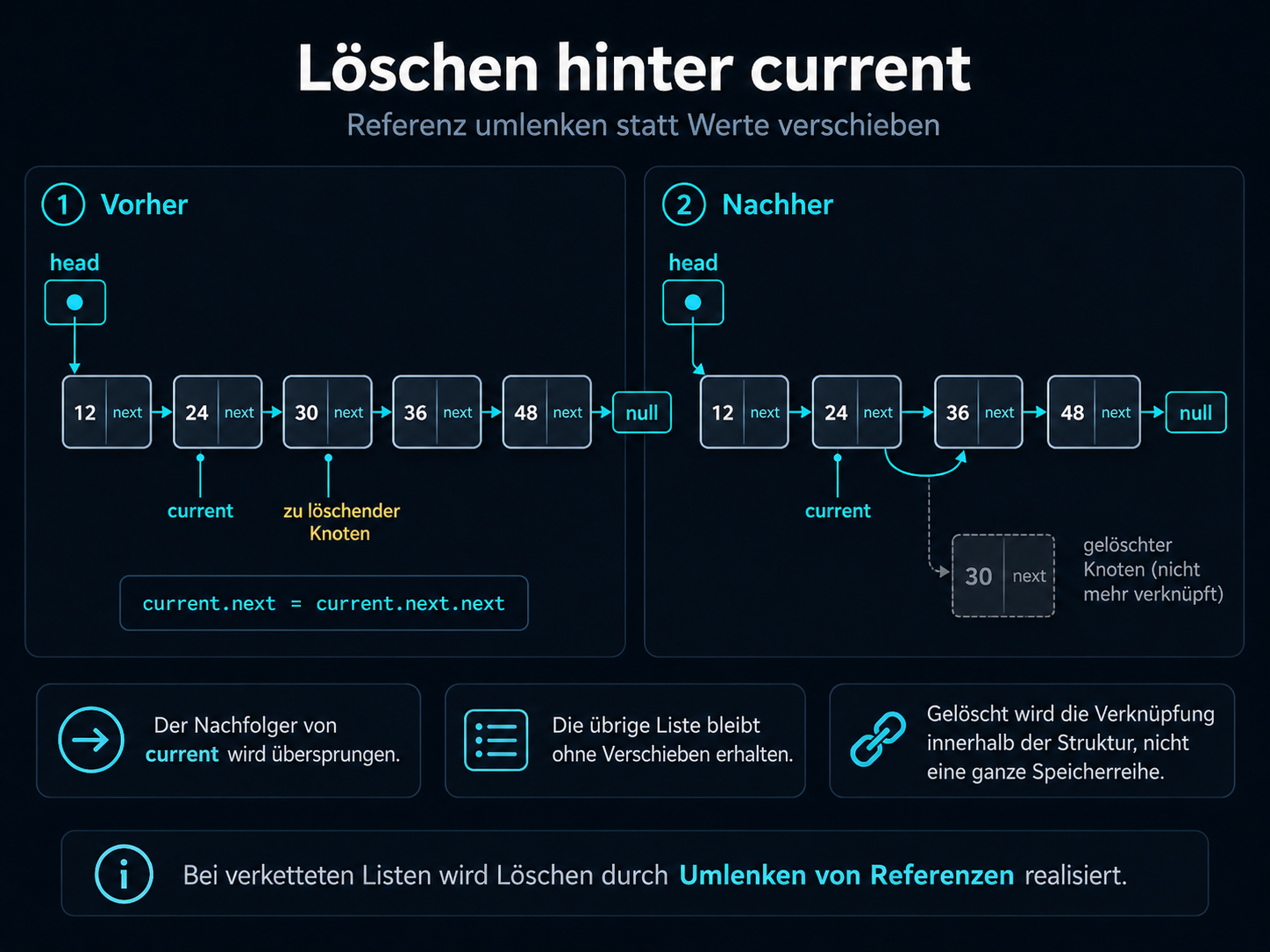
Lokales Löschen hinter current
Beim Löschen hinter current wird kein ganzer Speicherbereich verschoben. Stattdessen wird eine
Referenz so umgelenkt, dass der Nachfolger von current übersprungen wird.
Beim Löschen wird die Liste durch Umlenken einer Referenz geschlossen.
Der entfernte Knoten ist danach nicht mehr Teil der logischen Listenstruktur. Entscheidend ist: Die Liste bleibt
von head aus erreichbar, weil current nun direkt auf den nächsten relevanten Knoten verweist.
Der Renderer ergänzt diese Referenzlogik als dynamische Darstellung. Er ersetzt die Bilddeutung nicht, sondern
zeigt, wie die Operation im Ablauf gelesen werden kann.
Aktualisieren
current.value = neuerWert; ändert nur den Inhalt eines Knotens. Die Referenzen bleiben unverändert.
Das ist eine Inhaltsänderung, keine Strukturänderung.
Kapselung
Eine Listenklasse sollte nicht erlauben, dass fremder Code beliebig next-Referenzen verändert.
Methoden kapseln die Operationen und schützen die Listeninvariante.
Arbeitsauftrag: Zeichne die Liste 12 → 24 → 36 nach insertAfterCurrent, wenn current auf 24 zeigt.
Stack als LIFO-ADT Zugriffsbeschränkung am oberen Ende
Ein Stack ist nicht einfach „eine Liste, die senkrecht gezeichnet wird“. Als ADT legt er fest, dass nur ein
Zugriffspunkt frei ist: top. Neue Elemente werden mit push oben abgelegt,
pop entfernt genau das oberste Element, top oder peek liest es nur.
Operationen
push(value): oben einfügen
pop(): oberstes Element entfernen und liefern
top() / peek(): oberstes Element lesen
isEmpty(): Leere prüfen
LIFO
LIFO bedeutet last in, first out. Das zuletzt eingefügte Element wird zuerst entfernt.
Diese Regel entsteht aus der Zugriffsbeschränkung, nicht aus der Darstellung.
Vor dem Renderer steht die Vorfrage: Welches Element darf als nächstes entfernt werden, wenn nur top
zugänglich ist?
Stack-Anwendungen sind Browser-Zurück, Undo-Funktionen, Klammerprüfung und der Call-Stack aus Q1.3:
Rücksprunginformationen werden zuletzt abgelegt und zuerst wieder benötigt.
class Stack {
private Node top;
void push(int value) {
Node neu = new Node(value);
neu.next = top;
top = neu;
}
}
Objektorientiert nutzt ein Stack intern Knoten oder eine Liste, gibt aber nur Stack-Operationen frei.
Das ist das Geheimnisprinzip aus Q1.1: Die interne Struktur bleibt gekapselt.
Arbeitsauftrag: Begründe, warum pop beim Stack nicht auf ein beliebiges Element zugreifen darf.
Queue als FIFO-ADT Einfügen hinten, Entnehmen vorne
Eine Queue besitzt zwei definierte Enden: vorne front oder head, hinten tail.
Mit enqueue wird hinten eingefügt, mit dequeue vorne entnommen. Dadurch entsteht FIFO:
first in, first out.
Operationen
enqueue(value): hinten anfügen
dequeue(): vorne entfernen und liefern
front() / peek(): vorderes Element lesen
isEmpty(): Leere prüfen
Stack vs. Queue
Der Stack arbeitet an einem Ende. Die Queue arbeitet an zwei Enden: hinten wächst die Struktur,
vorne wird abgearbeitet. Das macht sie für faire Reihenfolgen geeignet.
Vor dem Renderer steht die Vorfrage: Welches Element muss als nächstes entnommen werden, damit die Ankunftsreihenfolge erhalten bleibt?
Typische Anwendungen sind Warteschlangen, Druckerwarteschlangen, Ticketsysteme, Ereignisverarbeitung und als Ausblick
Breitensuche (BFS). Auch hier gilt Kapselung: Die interne Liste wird nicht direkt manipuliert, sondern über
enqueue, dequeue und front genutzt.
class Queue {
private Node head;
private Node tail;
void enqueue(int value) {
Node neu = new Node(value);
if (tail != null) tail.next = neu;
tail = neu;
if (head == null) head = neu;
}
}
Arbeitsauftrag: Vergleiche Stack und Queue am Beispiel einer Aufgabenliste: Wann ist „zuletzt zuerst“ sinnvoll, wann „zuerst zuerst“?
Bäume und binäre Suchbäume Hierarchie, Rekursion, Traversierung und Ordnungsregel
Warum lineare Strukturen nicht reichen
Listen, Stacks und Queues organisieren Daten linear. Viele Probleme sind aber verzweigt: Ordner enthalten Unterordner,
Entscheidungen führen in unterschiedliche Suchräume, eine Organisation hat Über- und Unterordnungen. Dafür braucht man
Strukturen, in denen ein Knoten mehrere Nachfolger besitzen kann.
Vor dem Renderer steht die Vorfrage: Welche Beziehungen kann eine lineare Liste nur umständlich ausdrücken?
Grundbegriffe sauber lesen
Begriff
Bedeutung
Algorithmische Frage
Wurzel
Knoten ohne Elternknoten
Wo beginnt der Zugriff?
Knoten
Objekt mit Inhalt und Kindreferenzen
Welcher Wert wird verarbeitet?
Kante
Verbindung zwischen Eltern- und Kindknoten
Welcher Pfad ist möglich?
Blatt
Knoten ohne Kinder
Wo endet ein Such- oder Traversierungspfad?
Innerer Knoten
Knoten mit mindestens einem Kind
Wo verzweigt die Struktur?
Teilbaum
Knoten mit allen darunterliegenden Knoten
Welche kleinere Struktur ist wieder ein Baum?
Tiefe / Höhe
Abstand zur Wurzel bzw. längster Weg nach unten
Wie lang können Pfade werden?
Teilbäume als Brücke zu Q1.3
Jeder Teilbaum ist wieder ein Baum. Genau diese Selbstähnlichkeit greift Q1.3 auf: Basisfall,
Teilproblem und Rekursionsschritt lassen sich bei Baumoperationen besonders natürlich formulieren.
Q1.4 fragt zusätzlich, welche Datenstruktur diese Operation überhaupt trägt.
Ein binärer Baum hat pro Knoten höchstens zwei Kinder: linken und rechten Teilbaum. Dadurch werden Traversierungen
eindeutig beschreibbar: Preorder besucht zuerst den Knoten, Inorder zwischen linkem und rechtem Teilbaum,
Postorder nach den Teilbäumen.
Inorder liefert im binären Suchbaum eine sortierte Reihenfolge, weil die Ordnungsregel für jeden Knoten gilt:
links kleiner, rechts größer.
Binärer Suchbaum: Invariante und Operationen
Ein binärer Suchbaum ist ein binärer Baum mit Ordnungsregel. Diese Regel ist eine Invariante: Sie muss nach
Suchen, Einfügen, Löschen und Aktualisieren gültig bleiben. Eine Aktualisierung des Schlüssels ist deshalb
nicht beliebig harmlos; sie kann die Ordnungsregel verletzen und muss geprüft oder als Entfernen plus Einfügen modelliert werden.
Suchen
Jeder Vergleich entscheidet, ob links oder rechts weitergesucht wird. Der andere Teilbaum wird verworfen.
Einfügen
Einfügen ist eine Suche nach einem freien Kind entlang der Ordnungsregel. Der neue Knoten wird Blatt.
Löschen
Blatt entfernen, ein Kind hochziehen oder bei zwei Kindern mit Inorder-Nachfolger/-Vorgänger ersetzen.
Traversieren
Preorder, Inorder und Postorder beschreiben verschiedene Besuchsreihenfolgen derselben Struktur.
Die folgenden Rendererflächen zeigen die Operationen nicht als Dekoration, sondern als Lesespuren im Suchbaum.
Arbeitsauftrag: Führe die Inorder-Traversierung auf dem dargestellten BST durch und begründe, warum das Ergebnis sortiert ist.
Vergleich und begründete Strukturwahl Vom Operationsprofil zur Entscheidung
Strukturwahl ist keine Geschmackssache. Sie hängt davon ab, welche Operationen häufig sind, welche Invarianten
gelten und ob die Daten linear, zugriffsbeschränkt oder hierarchisch organisiert werden müssen.
Kriterium
Array-Liste
Verkettete Liste
Stack
Queue
Baum / BST
Struktur
linear, positionsbasiert
linear, referenzbasiert
linear, ein Zugriffspunkt
linear, zwei Zugriffspunkte
hierarchisch, verzweigt
Starker Fall
häufig get(i) oder set(i)
lokales Einfügen/Löschen nach gefundener Position
letzte Eingabe zuerst bearbeiten
erste Eingabe zuerst bearbeiten
Hierarchie oder geordneter Suchraum
Kritischer Fall
Einfügen/Löschen in der Mitte
Direktzugriff auf entfernte Position
Zugriff auf beliebiges Element
Zugriff auf beliebiges Element
unbalancierte oder ungültige Ordnung
Leitfrage
Brauche ich Positionsadressierung?
Kann ich über Pfade arbeiten?
Soll nur top sichtbar sein?
Soll Reihenfolge fair erhalten bleiben?
Gibt es Verzweigung oder Suchpfade?
Welche Struktur passt, wenn ...?
... häufig get(i) gebraucht wird?
Array-Liste, weil der Index direkten Zugriff ermöglicht.
... vorne häufig eingefügt und gelöscht wird?
Verkettete Liste, Stack oder Queue, abhängig von der erlaubten Zugriffsdisziplin.
... die letzte Aktion zuerst rückgängig gemacht wird?
Stack, weil LIFO genau dieses Muster erzwingt.
... Anfragen fair abgearbeitet werden?
Queue, weil FIFO die Ankunftsreihenfolge erhält.
... Daten hierarchisch organisiert sind?
Baum, weil Verzweigungen und Teilbäume modelliert werden können.
... dynamisch sortiert gesucht wird?
Binärer Suchbaum, wenn die Ordnungsregel erhalten bleibt.
Arbeitsauftrag: Entscheide für drei eigene Anwendungssituationen die passende Datenstruktur und begründe jeweils mit Operationen statt mit Namen.
Tool- und Sicherungsperspektive Darstellungen lesen, Operationen erklären, Auswahl begründen
Die PNG-Abbildungen sichern zentrale Referenzideen: Objektvariablen verweisen auf Objekte, Listen entstehen
durch next-Verweise, Einfügen sichert zuerst den alten Nachfolger und Löschen schließt die Liste
durch Referenzumlenkung. Die Renderer bleiben ergänzend wichtig, weil sie Operationen und Varianten im Seitenkontext
schrittweise darstellen.
Modell lesen
Markiere head, current, tail, value, next oder Baumbegriffe.
Operation beschreiben
Formuliere vor dem Code, welche Referenz, welcher Inhalt oder welcher Teilbaum verändert wird.
Pseudocode ergänzen
Ergänze fehlende Zuweisungen und prüfe, ob dabei Daten erreichbar bleiben.
Aufwand begründen
Beziehe die Laufzeit auf Indexzugriff, Traversieren, Endenzugriff oder Suchpfadlänge.
Der Rückbezug auf Q1.3 bleibt besonders im Baumteil wichtig: Viele Baumoperationen werden rekursiv formuliert.
Q1.4 erweitert diesen Blick um die Strukturfrage: Welche Organisation der Daten macht die Operation überhaupt passend?